Python数据科学分享——1.jupyter和python
Python数据科学生态中,Jupyter是一个非营利组织,旨在“为数十种编程语言的交互式计算开发开源软件,开放标准和服务”,目前主要包括三种交互式计算产品:Jupyter Notebook、JupyterHub和JupyterLab(Jupyter Notebook的下一代版本)。



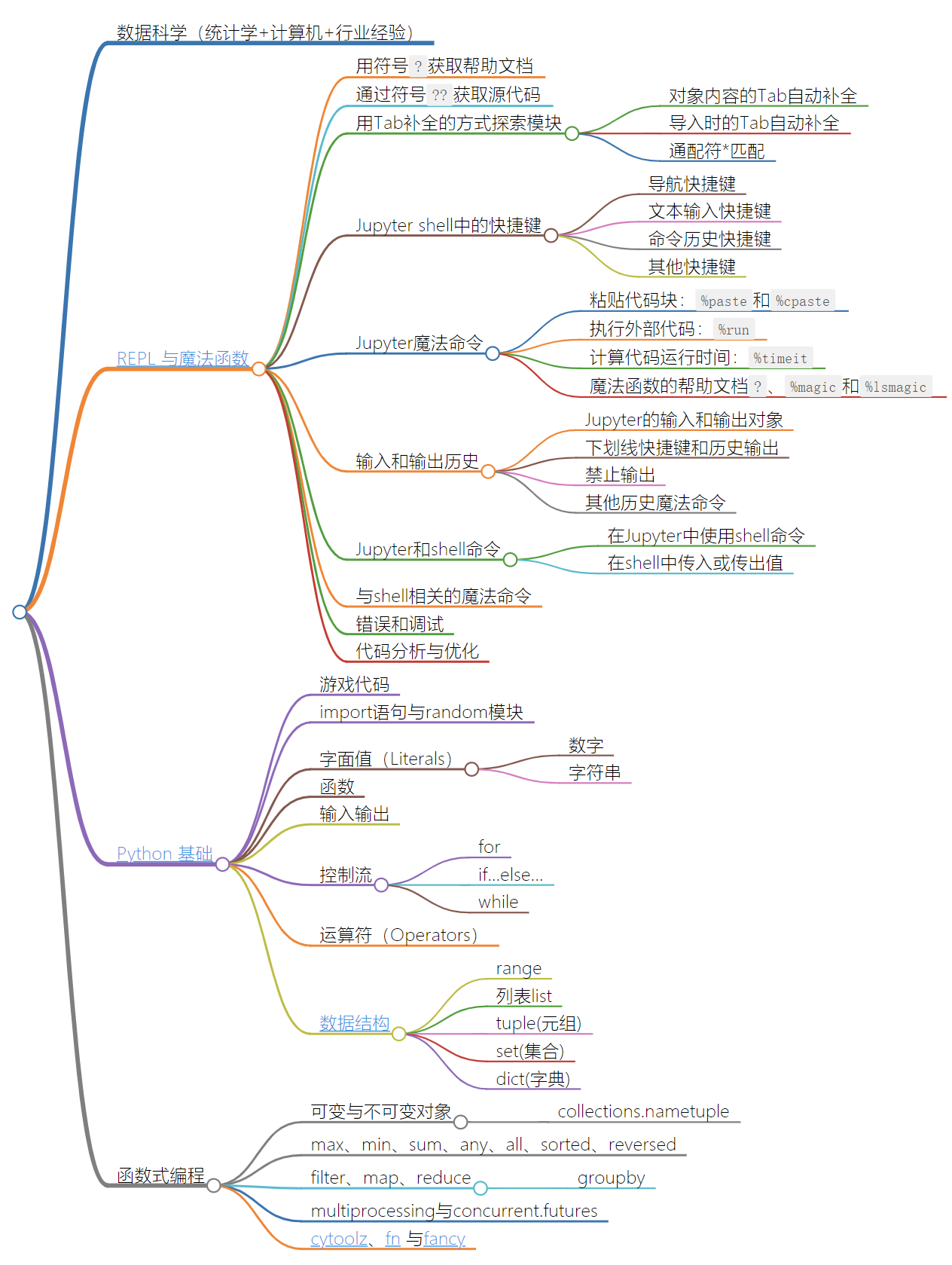
- 数据科学(统计学+计算机+行业经验)
- REPL 与魔法函数
- Python 基础
- 函数式编程
数据科学(统计学+计算机+行业经验)
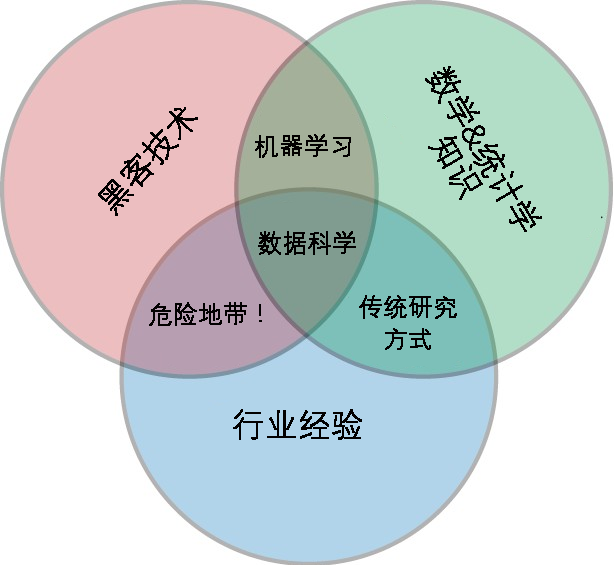
- 统计学家的能力——建立模型和聚合(数量不断增大的)数据
- 计算机科学家的能力——设计并使用算法对数据进行高效存储、分析和可视化
- 专业领域的能力——在细分领域中经过专业的训练,既可以提出正确的问题,又可以作出专业的解答
郁彬2020年2月发表论文《Verdical data science(靠谱的数据科学)》提出的数据科学三原则(PCS):
- 可预测性(predictability)
- 可计算性(computability)
- 稳定性(stability )
B. Yu and K. Kumbier (2020) Verdical data science PNAS. 117 (8), 3920-3929. QnAs with Bin Yu.
郁彬:统计学家,美国艺术与科学学院院士、美国国家科学院院士,加州大学伯克利分校统计系和电子工程与计算机科学系终身教授

-
Jupyter是一个非营利组织,旨在“为数十种编程语言的交互式计算开发开源软件,开放标准和服务”。2014年由Fernando Pérez从IPython中衍生出来。jupyter-console==IPython
-
Jupyter主要包括三种交互式计算产品:Jupyter Notebook、JupyterHub和JupyterLab(Jupyter Notebook的下一代版本)。
-
Jupyter Notebook(前身是IPython Notebook)是一个基于Web的交互式计算环境,用于创建Jupyter Notebook文档(JSON文档),由一组有序的输入/输出单元格列表构成,包含代码、文本(支持Markdown)、数学公式(Mathjax)、图表和富媒体,通常以“.ipynb”结尾扩展。
$\begin{align*} y = y(x,t) &= A e^{i\theta} \\ &= A (\cos \theta + i \sin \theta) \\ &= A (\cos(kx - \omega t) + i \sin(kx - \omega t)) \\ &= A\cos(kx - \omega t) + i A\sin(kx - \omega t) \\ &= A\cos \Big(\frac{2\pi}{\lambda}x - \frac{2\pi v}{\lambda} t \Big) + i A\sin \Big(\frac{2\pi}{\lambda}x - \frac{2\pi v}{\lambda} t \Big) \\ &= A\cos \frac{2\pi}{\lambda} (x - v t) + i A\sin \frac{2\pi}{\lambda} (x - v t) \end{align*}$
其中,$ \theta = kx - \omega t $
import altair as alt
from vega_datasets import data
source = data.cars()
brush = alt.selection(type="interval")
points = (
alt.Chart(source)
.mark_point()
.encode(
x="Horsepower:Q",
y="Miles_per_Gallon:Q",
color=alt.condition(brush, "Origin:N", alt.value("lightgray")),
)
.add_selection(brush)
)
bars = (
alt.Chart(source)
.mark_bar()
.encode(y="Origin:N", color="Origin:N", x="count(Origin):Q")
.transform_filter(brush)
)
points & bars
from ipywidgets import HBox, VBox, IntSlider, interactive_output
from IPython.display import display
a = IntSlider()
b = IntSlider()
out = interactive_output(lambda a, b: print(f"{a} * {b} = {a*b}"), {"a": a, "b": b})
display(HBox([VBox([a, b]), out]))
help(sorted)
IPython引入了?符号作为获取这个文档和其他相关信息的缩写:
sorted?
# Signature: sorted(iterable, /, *, key=None, reverse=False)
# Docstring:
# Return a new list containing all items from the iterable in ascending order.
# A custom key function can be supplied to customize the sort order, and the
# reverse flag can be set to request the result in descending order.
# Type: builtin_function_or_method
也适用于自定义函数或者其他对象!下面定义一个带有docstring的小函数:
def square(a):
"""返回a的平方"""
return a ** 2
square?
Jupyter提供了获取源代码的快捷方式(使用两个问号??):
square??
当查询C语言或其他编译扩展语言实现的函数时,??后缀=?后缀
sorted??
L = [1, 2, 3]
L.append
为了进一步缩小整个列表,可以输入属性或方法名称的第一个或前几个字符,然后Tab键将会查找匹配的属性或方法:
L.c<TAB>
L.clear L.copy L.count
L.co<TAB>
L.copy L.count如果只有一个选项,按下Tab键将会把名称自动补全。例如,下面示例中的内容将会马上被L.count替换:
L.cou<TAB>Python一般用前置下划线表示私有属性或方法。可以通过明确地输入一条下划线来把这些私有的属性或方法列出来:
L._<TAB>
L.__add__ L.__gt__ L.__reduce__
L.__class__ L.__hash__ L.__reduce_ex__为了简洁起见,这里只展示了输出的前两行,大部分是Python特殊的双下划线方法(昵称叫作“dunder方法”)。
from itertools import co<TAB>
combinations compress combinations_with_replacement count
同样,你也可以用Tab自动补全查看系统中所有可导入的包:
import <TAB>
import h<TAB>
str.*find*?
假设寻找一个字符串方法,它的名称中包含find,则可以这样做:
str.*find*?
str.find
str.rfind这里的
*符号匹配任意字符串,包括空字符串。
在实际应用过程中,灵活的通配符对于找命令非常有用。
粘贴代码块:%paste和%cpaste
当你使用Jupyter解释器时,粘贴多行代码块可能会导致错误,尤其是其中包含缩进和解释符号时。Jupyter的%paste魔法函数可以解决这个包含符号的多行输入问题:
In [1]: %paste
def donothing(x):... return x
## -- End pasted text --
%paste命令同时输入并执行该代码,所以你可以看到这个函数现在被应用了:
In [2]: donothing(10)
Out[2]: 10
另外一个作用类似的命令是%cpaste。该命令打开一个交互式多行输入提示,你可以在这个提示下粘贴并执行一个或多个代码块:
In [3]: %cpaste
Pasting code; enter '--' alone on the line to stop or use Ctrl-D.
:>>> def donothing(x):
:... return x
:--%%file myscript.py
def square(x):
"""求平方"""
return x ** 2
for N in range(1, 4):
print(N, "squared is", square(N))
ls myscript.py
%run myscript.py
当你运行了这段代码之后,该代码中包含的所有函数都可以在Jupyter会话中使用:
square(5)
%timeit L = [n ** 2 for n in range(1000)]
%timeit会自动多次执行命令以获得更稳定的结果。
对于多行语句,可以加入第二个%符号将其转变成单元魔法,以处理多行输入。例如,下面是for循环的同等结构:
%%timeit
L = []
for n in range(1000):
L.append(n ** 2)
从以上结果可以立刻看出,列表解析式比同等的for循环结构快约20%。
%magic
import math
math.sin(2)
math.cos(2)
Jupyter实际上创建了叫作In和Out的Python变量,这些变量自动更新以反映命令历史:
# In
# Out
In对象是一个列表,按照顺序记录所有的命令(列表中的第一项是一个占位符,以便In[1]可以表示第一条命令):
print(In[1])
Out对象不是一个列表,而是一个字典。它将输入数字映射到相应的输出(如果有的话):
print(Out[2])
不是所有操作都有输出,例如
import语句和None。任何返回值是None的命令都不会加到Out变量中。
如果想利用之前的结果,理解以上内容将大有用处。例如,利用之前的计算结果检查sin(2) ** 2和cos(2) ** 2的和,结果如下:
Out[2] ** 2 + Out[3] ** 2
print(_)
Jupyter可以用两条下划线获得倒数第二个历史输出,用三条下划线获得倒数第三个历史输出(跳过任何没有输出的命令):
print(__)
print(___)
另外,Out[X]可以简写成_X(即一条下划线加行号):
Out[2]
_2
math.sin(2) + math.cos(2);
这个结果被计算后,输出结果既不会显示在屏幕上,也不会存储在
Out中:
25 in Out
%history -n 1-4
按照惯例,可以输入%history?来查看更多相关信息以及可用选项的详细描述。其他类似的魔法命令还有%rerun(该命令将重新执行部分历史命令)和%save(该命令将部分历史命令保存到一个文件中)。如果想获取更多相关信息,建议你使用?帮助功能(详情请参见1.2节)。
!ls
!pwd
!echo "数据科学"
contents = !ls
contents
directory = !pwd
directory
这些结果并不以列表的形式返回,虽然可以像列表一样操作,但是这种类型还有其他功能,例如grep和fields方法以及s、n和p属性,允许你轻松地搜索、过滤和显示结果。
type(directory)
另一个方向的交互,即将Python变量传入shell,可以通过{varname}语法实现:
message = "美妙的Python"
!echo {message}
变量名包含在大括号内,在shell命令中用实际的变量替代。
%cd ..
其实可以直接用cd实现该功能:
cd ..
这种方式称作自动魔法(automagic)函数,可以通过%automagic魔法函数进行调整,默认开启。
除了%cd,其他可用的类似shell的魔法函数还有%cat、%cp、%env、%ls、%man、%mkdir、%more、%mv、%pwd、%rm和%rmdir,默认都可以省略%符号。
错误和调试
代码开发和数据分析经常需要一些调试,Jupyter调试代码工具:
-
%xmode:控制打印信息进行traceback -
%debug:基于ipdb(pdb增强版)专用的调试器进行调试 -
%run -d:交互式模式运行脚本,用next命令单步向下交互地运行代码
常用调试命令如下:
| 命令 | 描述 |
|---|---|
list |
显示文件的当前路径 |
h(elp) |
显示命令列表,或查找特定命令的帮助信息 |
q(uit) |
退出调试器和程序 |
c(ontinue) |
退出调试器,继续运行程序 |
n(ext) |
跳到程序的下一步 |
<enter> |
重复前一个命令 |
p(rint) |
打印变量 |
s(tep) |
步入子进程 |
r(eturn) |
从子进程跳出 |
在调试器中使用help命令,或者查看ipdb的在线文档获取更多的相关信息
代码分析与优化
“过早优化是一切罪恶的根源。”——高德纳
Jupyter提供了很多执行这些代码计时和分析的操作函数。
-
%time:对单个语句的执行时间进行计时 -
%timeit:对单个语句的重复执行进行计时,以获得更高的准确度 -
%prun:利用分析器运行代码 -
%lprun:利用逐行分析器运行代码,需要先安装pip install line_profiler,再导入%load_ext line_profiler -
%memit:测量单个语句的内存使用,需要先安装pip install memory_profiler,再导入%load_ext memory_profiler
-
%mprun:通过逐行的内存分析器运行代码

# 猜数字游戏
import random
m, n = 30, 5 # 最大值和猜测次数
x = random.randrange(1, m)
name = input("Hello! 你是谁?")
print(f"欢迎你,{name}同学,我在1到{m}之间选了一个整数,共{n}次机会,你猜猜看?")
for i in range(n):
guess = int(input(f"{name}同学猜是:"))
if guess == x:
print(f"猜中啦,{name}同学!就是{x},赶紧去买注大乐透吧!")
break
else:
print("猜大了~", end="") if guess > x else print("猜小了~", end="")
print(f"还有{n-i-1}次机会,再猜猜看:") if i + 1 < n else print("")
else:
print(f">:<没猜中,我想的是{x}啊!")
# 猜数字游戏
第2行是import语句,导入了一个random模块(module)
import random
语句(statement)是执行操作的若干指令,而表达式(expression)会计算并返回值
第4行是赋值(assignment)语句,将30、5保存在变量(variable)m、n中
m, n = 30, 5 # 最大值和猜测次数
3 + 4 * 5 / 6
20 // 3, 20 % 3, 20 ** 3
import sys
sys.float_info
字符串有多种形式,可以使用单引号(''),双引号(""),反斜杠 \ 表示转义字符:
print("C:\some\name")
字符串跨行连续输入。用三重引号:"""...""" 或 '''...'''。字符串中的回车换行会自动包含到字符串中,如果不想包含,在行尾添加一个 \ 即可。如下例:
print("""\
Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to
""")
字符串可以用 + 进行连接(粘到一起),也可以用 * 进行重复
3 * "un" + "ium"
很长的字符串用括号包裹多个片段即可:
text = ('很长的字符串用括号'
'包裹多个片段即可')
text
x = random.randrange(1, m)
# 定义 Fibonacci数列
def fib(n):
"""Print a Fibonacci series up to n."""
a, b = 0, 1
while a < n:
print(a, end=" ")
a, b = b, a + b
print()
# 调用函数
fib(2000)
函数通过return语句返回值,即使没有 return 语句的函数也会返回一个值None
# 定义 Fibonacci数列
def fib_return(n):
"""Print a Fibonacci series up to n."""
a, b = 0, 1
fib = []
while a < n:
fib.append(a)
a, b = b, a + b
return fib
fib2000 = fib_return(2000)
fib2000
random.randrange??
第6行input()函数获取用户输入
name = input("Hello! 你是谁?")
name
第7行print()函数打印输出,f字符串可以在{ 和 } 字符之间引用变量或表达式(Python3.6新特性,另外还有C语言%字符串与.format字符串)
print(f"欢迎你,{name}同学,我在1到{m}之间选了一个整数,共{n}次机会,你猜猜看?")
def mod(a,b):
return a % b
import dis
dis.dis(mod)
mod('hello%s','world')
print(f"{1+2*3}")
更常见的还有文件读写操作:
with open("myscript.py", "r") as f:
txt = f.read()
print(txt)
with open("myscript2.py", "w") as f:
f.write(txt)
cat myscript2.py
with open("myscript.py", "r") as f:
txt = f.readlines()
txt
with open("myscript2.py", "w") as f:
f.writelines(txt)
cat myscript2.py
for i in range(10):
print(i ** 2)
else:
print("game over")
for i in range(10):
if i > 5:
break
print(i ** 2)
else:
print("game over")
for i in range(10):
if i > 5:
continue
print(i ** 2)
else:
print("game over")
m = 5.1
if m < 5:
print(f"{m}小于5")
elif m % 2 == 1:
print(f"{m}是奇数")
elif m % 2 == 0:
print(f"{m}是偶数")
else:
print("不是整数")
5.1 % 2
浮点数精度问题,建议参考decimal标准库
鲜为人知的Python特性 https://github.com/satwikkansal/wtfpython
i = 0
while i < 10:
if i > 5:
break
print(i ** 2)
i += 1
else:
print("game over")
运算符 |
描述 |
|---|---|
|
赋值表达式 |
lambda 表达式 |
|
|
条件表达式 |
布尔逻辑或 OR |
|
布尔逻辑与 AND |
|
|
布尔逻辑非 NOT |
比较运算,包括成员检测和标识号检测 |
|
|
按位或 OR |
|
按位异或 XOR |
|
按位与 AND |
|
移位 |
|
加和减 |
|
乘,矩阵乘,除,整除,取余 |
|
正,负,按位非 NOT |
|
乘方 |
|
await 表达式 |
|
抽取,切片,调用,属性引用 |
|
|
绑定或加圆括号的表达式,列表显示,字典显示,集合显示 |
条件表达式也称三元运算符(ternary operator):
cmp = "2 > 1" if 2 > 1 else "2 < 1"
cmp
第14、15行均使用了条件表达式:
print("猜大了~", end="") if guess > x else print("猜小了~", end="")
print(f"还有{n-i-1}次机会,再猜猜看:") if i + 1 < n else print("")
数据结构
- range
- list(列表)
- tuple(元组)
- set(集合)
- dict(字典)
range(10)
type(range(10))
tuple(range(10))
harry_potter = [
"魔法石",
"密室",
"阿兹卡班囚徒",
"火焰杯",
"凤凰社",
"混血王子",
"死亡圣器",
"被诅咒的孩子",
]
harry_potter
type(harry_potter)
len(harry_potter)
harry_potter.index("凤凰社")
harry_potter[4]
harry_potter.pop()
harry_potter
harry_potter.append("被诅咒的孩子")
harry_potter
for book in harry_potter:
print(f"《哈利·波特与{book}》")
[f"《哈利·波特与{book}》" for book in harry_potter]
harry_potter = (
("哈利·波特", "魔法石"),
("哈利·波特", "密室"),
("哈利·波特", "阿兹卡班囚徒"),
("哈利·波特", "火焰杯"),
("哈利·波特", "凤凰社"),
("哈利·波特", "混血王子"),
("哈利·波特", "死亡圣器"),
("哈利·波特", "被诅咒的孩子"),
)
for i, book in enumerate(harry_potter):
print(f"第{i+1}本《{'与'.join(book)}》")

"哈利" in {"哈利", "波特"}
- 从序列中去除重复项
set(("哈利", "波特", "哈利", "波特"))
- 数学集合交、并、补等运算
harry_potter_books = set(x for y in harry_potter for x in y)
harry_potter_books
magic, secret = set(harry_potter[0]), set(harry_potter[1])
magic, secret
magic & harry_potter_books
harry_potter_books - magic
magic | secret
magic ^ secret
magic.add("死亡圣器")
magic
frozenset不可变对象,不支持add、remove、pop和update等操作
magic2 = frozenset(magic)
magic2
magic2.add
harry_potter1 = dict(
魔法石=1997, 密室=1998, 阿兹卡班囚徒=1999, 火焰杯=2000, 凤凰社=2003, 混血王子=2005, 死亡圣器=2007,
)
harry_potter2 = {
"魔法石": 1997,
"密室": 1998,
"阿兹卡班囚徒": 1999,
"火焰杯": 2000,
"凤凰社": 2003,
"混血王子": 2005,
"死亡圣器": 2007,
}
harry_potter1 == harry_potter2
harry_potter3 = dict(
zip(
("魔法石", "密室", "阿兹卡班囚徒", "火焰杯", "凤凰社", "混血王子", "死亡圣器",),
(1997, 1998, 1999, 2000, 2003, 2005, 2007,),
)
)

harry_potter1 == harry_potter2 == harry_potter3
harry_potter2["凤凰社"]
for book, year in harry_potter2.items():
print(f"《哈利·波特与{book}》出版于{year}年")
harry_potter2["被诅咒的孩子"] = 2016
harry_potter2
harry_potter2.pop("被诅咒的孩子")
harry_potter2
tup = ([3, 4, 5], 'two')
tup[0][-1] = 1
tup
| symbol | name | current | percent | pe_ttm | current_year_percent | volume | |
|---|---|---|---|---|---|---|---|
| 0 | SH601398 | 工商银行 | 5.17 | 0.39 | 5.855 | -12.07 | 104063910 |
| 1 | SH601939 | 建设银行 | 6.43 | 0.16 | 5.939 | -11.07 | 51089825 |
| 2 | SH600519 | 贵州茅台 | 1265.70 | -0.72 | 36.908 | 6.99 | 2466087 |
| 3 | SH601318 | 中国平安 | 74.46 | 0.62 | 10.474 | -12.87 | 48625473 |
| 4 | SH601288 | 农业银行 | 3.46 | 0.58 | 5.631 | -6.23 | 118473509 |
| 5 | SH601988 | 中国银行 | 3.48 | 0.58 | 5.420 | -5.69 | 79563490 |
| 6 | SH600036 | 招商银行 | 35.09 | 0.20 | 9.274 | -6.63 | 71533247 |
| 7 | SH601857 | 中国石油 | 4.44 | 1.37 | 42.328 | -23.84 | 85973295 |
| 8 | SH601628 | 中国人寿 | 28.54 | -0.73 | 16.348 | -18.15 | 16644522 |
| 9 | SH600028 | 中国石化 | 4.46 | 0.45 | 23.430 | -12.72 | 119640204 |
data = [{"symbol": "SH601398","name": "工商银行","current": 5.17,"percent": 0.39,"pe_ttm": 5.855,"current_year_percent": -12.07,"volume": 104063910,"industry": "银行",},
{"symbol": "SH601939","name": "建设银行","current": 6.43,"percent": 0.16,"pe_ttm": 5.939,"current_year_percent": -11.07,"volume": 51089825,"industry": "银行",},
{"symbol": "SH600519","name": "贵州茅台","current": 1265.7,"percent": -0.72,"pe_ttm": 36.908,"current_year_percent": 6.99,"volume": 2466087,"industry": "白酒",},
{"symbol": "SH601318","name": "中国平安","current": 74.46,"percent": 0.62,"pe_ttm": 10.474,"current_year_percent": -12.87,"volume": 48625473,"industry": "保险",},
{"symbol": "SH601288","name": "农业银行","current": 3.46,"percent": 0.58,"pe_ttm": 5.631,"current_year_percent": -6.23,"volume": 118473509,"industry": "银行",},
{"symbol": "SH601988","name": "中国银行","current": 3.48,"percent": 0.58,"pe_ttm": 5.42,"current_year_percent": -5.69,"volume": 79563490,"industry": "银行",},
{"symbol": "SH600036","name": "招商银行","current": 35.09,"percent": 0.2,"pe_ttm": 9.274,"current_year_percent": -6.63,"volume": 71533247,"industry": "银行",},
{"symbol": "SH601857","name": "中国石油","current": 4.44,"percent": 1.37,"pe_ttm": 42.328,"current_year_percent": -23.84,"volume": 85973295,"industry": "石化",},
{"symbol": "SH601628","name": "中国人寿","current": 28.54,"percent": -0.73,"pe_ttm": 16.348,"current_year_percent": -18.15,"volume": 16644522,"industry": "保险",},
{"symbol": "SH600028","name": "中国石化","current": 4.46,"percent": 0.45,"pe_ttm": 23.43,"current_year_percent": -12.72,"volume": 119640204,"industry": "石化",}]
from collections import namedtuple
Stocks = namedtuple(
"Stocks",
[
"symbol",
"name",
"current",
"percent",
"pe_ttm",
"current_year_percent",
"volume",
"industry",
],
)
Stocks
icbc = Stocks(
symbol="SH601398",
name="工商银行",
current=5.17,
percent=0.39,
pe_ttm=5.855,
current_year_percent=-12.07,
volume=104063910,
industry="银行",
)
icbc
icbc.name
icbc.name = 'dd'
stocks = tuple(Stocks(**_) for _ in data)
stocks
stocks[0].name
max(stocks)
max(stocks, key=lambda _: _.current)
min(stocks)
min(stocks, key=lambda _: _.current)
sum((1, 2, 3, 0))
any((1, 2, 3, 0))
all((1, 2, 3, 0))
sorted(stocks, key=lambda _: _.current)
tuple(reversed(stocks))
tuple(filter(lambda s: s.current > 5, stocks))
tuple(s for s in stocks if s.current > 5)
tuple(map(lambda s: (s.name, round(s.volume / 10000, 1)), stocks))
tuple((s.name, round(s.volume / 10000, 1)) for s in stocks)
from functools import reduce
reduce?
reduce(lambda acc, v: acc + v.volume, stocks, 0)
from itertools import accumulate
tuple(accumulate(s.volume for s in stocks))
def box(acc, v):
acc[v.industry].append(v.name)
return acc
stocks_industry = reduce(box, stocks, {"银行": [], "保险": [], "白酒": [], "石化": []})
stocks_industry
from collections import defaultdict
stocks_industry = reduce(box, stocks, defaultdict(list))
stocks_industry
stocks_industry = reduce(
lambda acc, v: {**acc, **{v.industry: acc[v.industry] + [v.name]}},
stocks,
{"银行": [], "白酒": [], "保险": [], "石化": []},
)
stocks_industry
from itertools import groupby
{
k: [_.name for _ in s]
for k, s in groupby(
sorted(stocks, key=lambda s: s.industry), key=lambda s: s.industry
)
}
import time
import os
import multiprocessing
def cmpt_open(x):
print(f"进程:{os.getpid()} 正在计算 {x.name}")
time.sleep(1)
rst = {"name": x.name, "open": x.current / (1 + x.percent * 0.01)}
print(f"进程:{os.getpid()} 完成计算 {x.name}")
return rst
%%time
result = tuple(map(cmpt_open, stocks))
result
%%time
pool = multiprocessing.Pool()
result = pool.map(cmpt_open, stocks)
result
import concurrent.futures
%%time
with concurrent.futures.ProcessPoolExecutor() as pool:
result = pool.map(cmpt_open, stocks)
tuple(result)
%%time
with concurrent.futures.ThreadPoolExecutor() as pool:
result = pool.map(cmpt_open, stocks)
tuple(result)
from cytoolz import map, concat, frequencies # cytoolz 的 map 默认惰性计算
%%time
frequencies(
concat(map(str.upper, open("tale-of-two-cities.txt", "r", encoding="utf-8-sig")))
)
from collections import Counter
%%time
Counter(
map(str.upper, open("tale-of-two-cities.txt", "r", encoding="utf-8-sig").read())
)