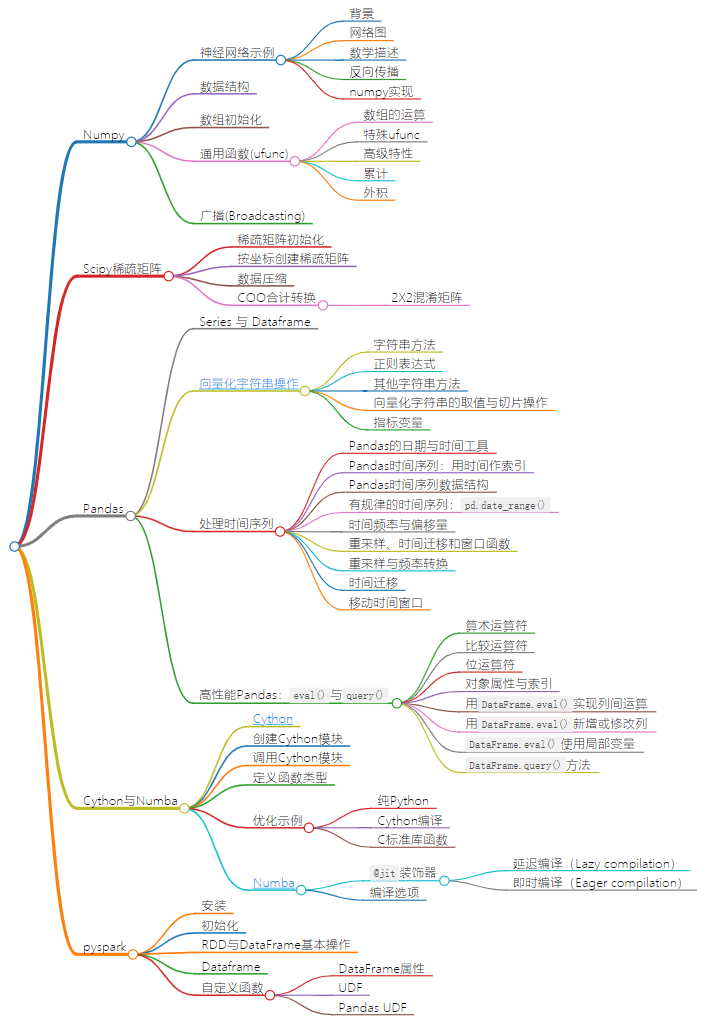
Python数据科学分享——2.数据处理
Python数据处理历史悠久,除了基础的Numpy、Scipy、pandas构建繁荣生态,还有谷歌推出的tensorflow、jax高性能工具



- Numpy
- Scipy稀疏矩阵
- Pandas
- Cython与Numba
- pyspark
%load_ext autoreload
%autoreload 2
import matplotlib.pyplot as plt
import seaborn
seaborn.set()
plt.rcParams["font.sans-serif"] = ["SimHei"]
import numpy as np
import pandas as pd
from scipy import sparse
from tqdm.notebook import tqdm
| 首发年份 | 名称 | 场景 |
|---|---|---|
| 1991 | Python | 编程语言 |
| 2001 | ipython | 增强shell |
| 2001 | SciPy | 算法库 |
| 2006 | Numpy | 数组运算 |
| 2007 | Cython | AOT静态编译 |
| 2008 | Pandas | 标签数组运算 |
| 2010 | scikit-learn | 机器学习 |
| 2012 | ipython notebook | 计算环境 |
| 2012 | anaconda | 管理工具 |
| 2012 | Numba | llvm实现JIT编译器 |
| 2012 | pyspark | 集群运算 |
| 2015 | jupyter | 多语言支持 |
| 2015 | TensorFlow | 深度学习 |
| 2018 | jax | Numpy+autogrd+JIT+GPU+TPU |
from IPython.display import Video
# https://github.com/Sentdex/NNfSiX
# Video("2.data-elt/cat_neural_network.mp4", embed=True)
| x1 | x2 | x3 | Y |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 |
X = np.array([[0, 0, 1], [0, 1, 1], [1, 0, 1], [1, 1, 1]])
y = np.array([[0], [1], [1], [0]])
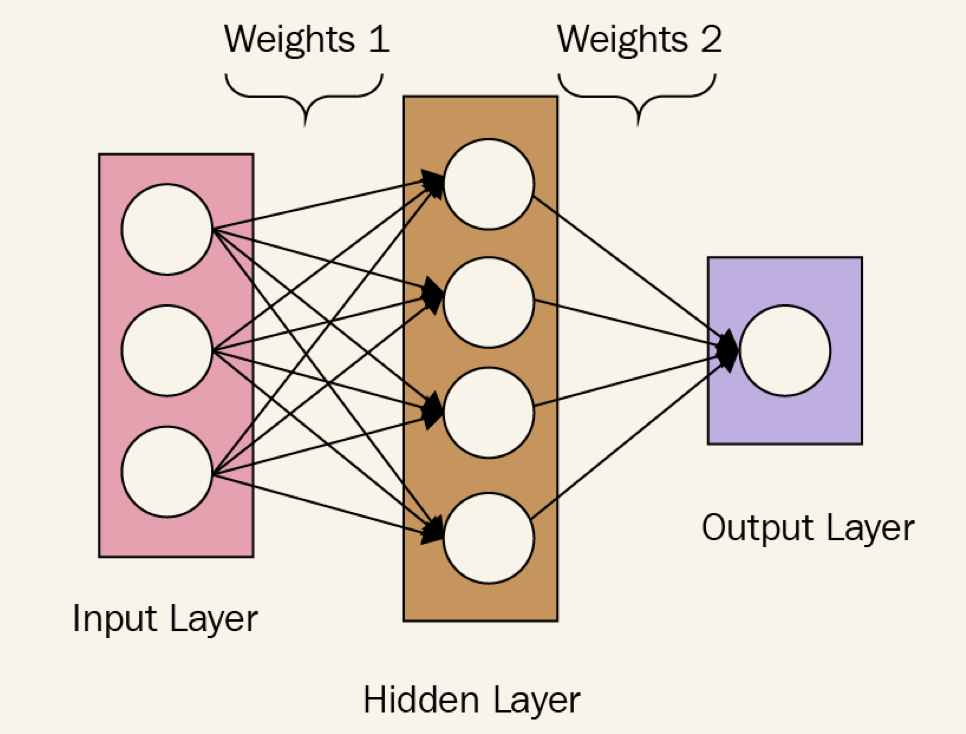
公式1 $$ \hat y = \sigma(W_2\sigma(W_1x+ b_1) + b_2) $$
公式2(sigmoid) $$ \sigma = \frac {1} {1 + e^{-x}} $$
公式3(sigmoid导数) $$ \sigma' = \sigma(x) \times (1 - \sigma(x)) $$
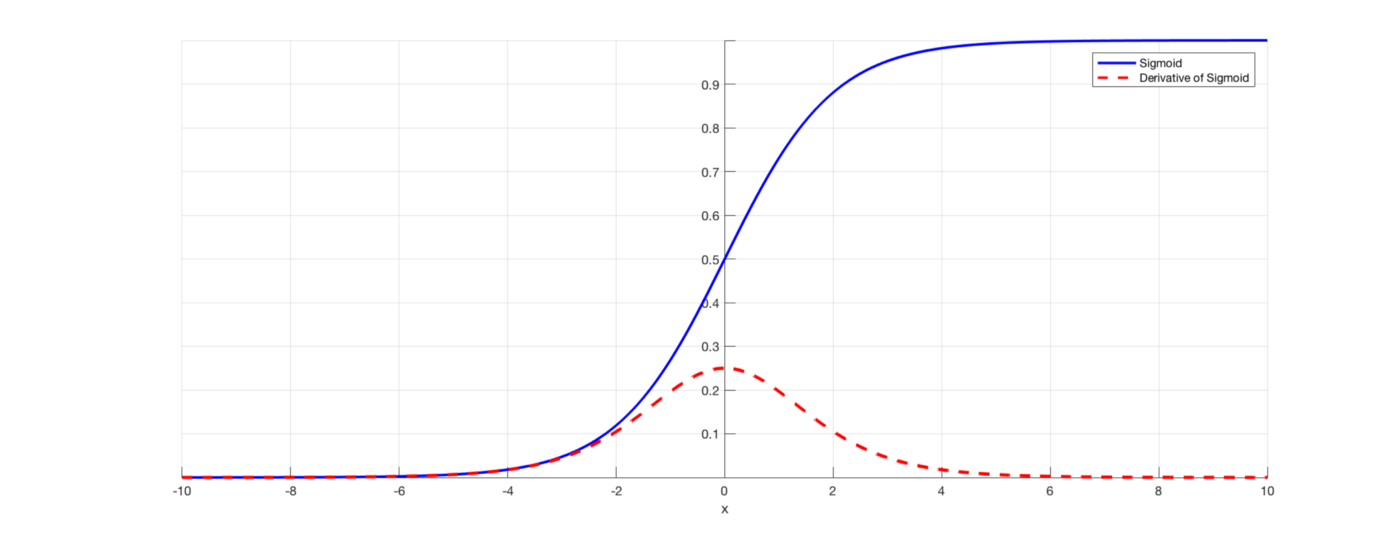

公式4 $$ Loss(Sum\ of\ Squares\ Error) = \sum_{i=1}^n(y-\hat y)^2 $$
def σ(x):
return 1 / (1 + np.exp(-x))
def σ_dvt(x):
return σ(x) * (1 - σ(x))
class NeuralNetwork(object):
def __init__(self, x, y):
self.x = x
self.y = y
self.w1 = np.random.rand(self.x.shape[1], 4)
self.w2 = np.random.rand(4, 1)
self.yhat = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = σ(self.x @ self.w1)
self.yhat = σ(self.layer1 @ self.w2)
def backprop(self):
gd = 2 * (self.y - self.yhat) * σ_dvt(self.yhat)
d_w2 = self.layer1.T @ gd
d_w1 = self.x.T @ (gd @ (self.w2.T) * σ_dvt(self.layer1))
self.w1 += d_w1
self.w2 += d_w2
nn = NeuralNetwork(X, y)
train = []
for i in tqdm(range(10000)):
nn.feedforward()
nn.backprop()
loss = sum((_[0] - _[1])[0] ** 2 for _ in zip(nn.y, nn.yhat))
train.append(loss)
print(nn.yhat)
def show_plot(x, y):
plt.figure(figsize=(15, 5))
plt.plot(
x,
y,
linewidth=3,
linestyle=":",
color="blue",
label="Sum of Squares Error",
)
plt.xlabel("训练次数")
plt.ylabel("训练损失")
plt.title("训练损失随次数增加而递减")
plt.legend(loc="upper right")
plt.show()
show_plot(range(len(train)), train)

show_plot(range(4000, len(train)), train[4000:])

# 创建一个长度为10的数组,数组的值都是0
np.zeros(10, dtype=int)
# 创建一个3x5的浮点型数组,数组的值都是1
np.ones((3, 5), dtype=float)
# 创建一个3x5的浮点型数组,数组的值都是3.14
np.full((3, 5), 3.14)
# 创建一个线性序列数组,从0开始,到20结束,步长为2(它和内置的range()函数类似)
np.arange(0, 20, 2)
# 创建一个5个元素的数组,这5个数均匀地分配到0~1区间
np.linspace(0, 1, 5)
# NumPy的随机数生成器设置一组种子值,以确保每次程序执行时都可以生成同样的随机数组:
np.random.seed(1024)
# 创建一个3x3的、0~1之间均匀分布的随机数组成的数组
np.random.random((3, 3))
# 创建一个3x3的、均值为0、标准差为1的正态分布的随机数数组
np.random.normal(0, 1, (3, 3))
# 创建一个3x3的、[0, 10)区间的随机整型数组
np.random.randint(0, 10, (3, 3))
# 创建一个3x3的单位矩阵
np.eye(3)
# 创建一个由3个整型数组成的未初始化的数组,数组的值是内存空间中的任意值
np.empty(3)
- 属性:确定数组的大小、形状、存储大小、数据类型
- 读写:数组保存与加载文件
- 数学运算:加减乘除、指数与平方根、三角函数、聚合比较等基本运算
- 复制与排序:数组深浅copy、快速排序、归并排序和堆排序
- 索引:获取和设置数组各个元素的值
- 切分:在数组中获取或设置子数组
- 变形:改变给定数组的形状
- 连接和分裂:将多个数组合并为一个,或者将一个数组分裂成多个

通用函数(universal functions, ufunc)
NumPy实现一种静态类型、可编译程序接口(ufunc),实现向量化(vectorize)操作,避免for循环,提高效率,节约内存。
通用函数有两种存在形式:
- 一元通用函数(unary ufunc)对单个输入操作
- 二元通用函数(binary ufunc)对两个输入操作
数组的运算
NumPy通用函数的使用方式非常自然,因为它用到了Python原生的算术运算符(加、减、乘、除)、绝对值、三角函数、指数与对数、布尔/位运算符。
| 运算符 | 对应的通用函数 | 描述 |
|---|---|---|
+ |
np.add |
加法运算(即1 + 1 = 2) |
- |
np.subtract |
减法运算(即3 - 2 = 1) |
- |
np.negative |
负数运算 (即-2) |
* |
np.multiply |
乘法运算 (即2 * 3 = 6) |
/ |
np.divide |
除法运算 (即3 / 2 = 1.5) |
// |
np.floor_divide |
地板除法运算(floor division,即3 // 2 = 1) |
** |
np.power |
指数运算 (即2 ** 3 = 8) |
% |
np.mod |
模/余数 (即9 % 4 = 1) |
np.abs |
绝对值 |
x = np.arange(4)
print("x =", x)
print("x + 5 =", x + 5)
print("x - 5 =", x - 5)
print("x * 2 =", x * 2)
print("x / 2 =", x / 2)
print("x // 2 =", x // 2) # 整除运算
x = [1, 2, 3]
print("x =", x)
print("e^x =", np.exp(x))
print("2^x =", np.exp2(x))
print("3^x =", np.power(3, x))
print("x =", x)
print("ln(x) =", np.log(x))
print("log2(x) =", np.log2(x))
print("log10(x) =", np.log10(x))
from scipy import special
x = [1, 5, 10]
print("gamma(x) =", special.gamma(x))
print("ln|gamma(x)| =", special.gammaln(x))
print("beta(x, 2) =", special.beta(x, 2))
x = np.arange(1, 6)
np.add.reduce(x)
同样,对multiply通用函数调用reduce方法会返回数组中所有元素的乘积:
np.multiply.reduce(x)
np.add.accumulate(x)
np.multiply.accumulate(x)
NumPy提供了专用的函数(
np.sum、np.prod、np.cumsum、np.cumprod),它们也可以实现reduce的功能
x = np.arange(1, 10)
np.multiply.outer(x, x)
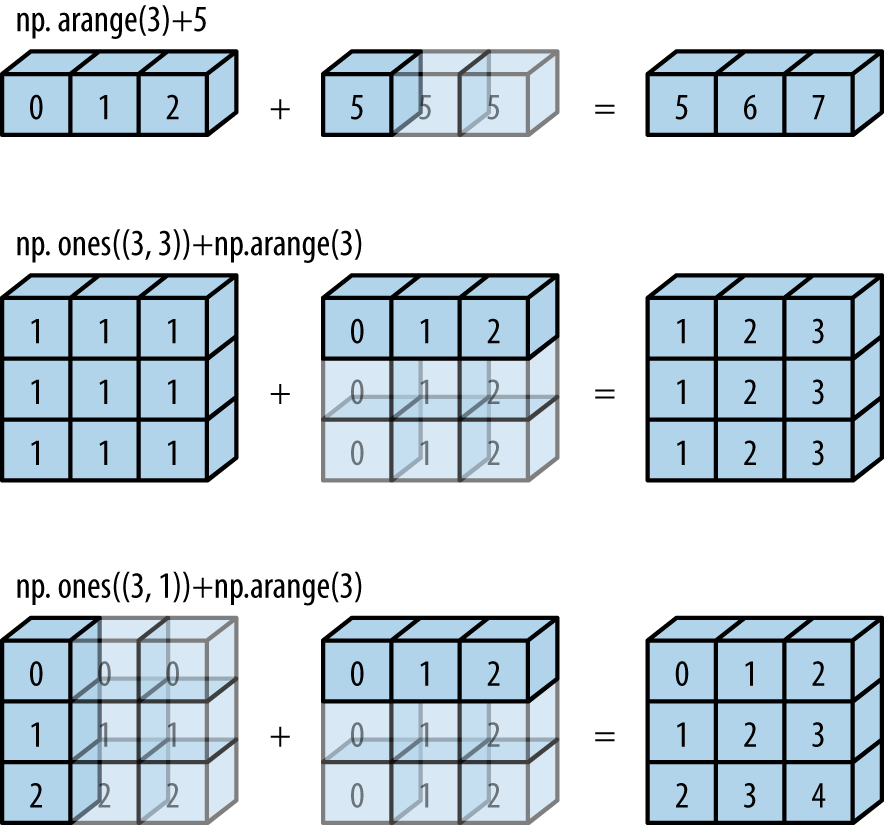
a = np.arange(3)
a + 5
np.ones((3, 3)) + a
根据规则1,数组a的维度数更小,所以在其左边补1:
b.shape -> (3, 3)
a.shape -> (1, 3)
根据规则2,第一个维度不匹配,因此扩展这个维度以匹配数组:
b.shape -> (3, 3)
a.shape -> (3, 3)
现在两个数组的形状匹配了,可以看到它们的最终形状都为(3, 3):
b = np.arange(3)[:, np.newaxis]
b + a
根据规则1,数组a的维度数更小,所以在其左边补1:
b.shape -> (3, 1)
a.shape -> (1, 3)
根据规则2,两个维度都不匹配,因此扩展这个维度以匹配数组:
b.shape -> (3, 3)
a.shape -> (3, 3)
现在两个数组的形状匹配了,可以看到它们的最终形状都为(3, 3):

SN = np.random.poisson(0.2, (10, 10)) * np.random.randint(0, 10, (10, 10))
SN
rows, cols = np.nonzero(SN)
vals = SN[rows, cols]
rows, cols, vals
X = sparse.coo_matrix(SN)
X
print(X)
X2 = sparse.coo_matrix((vals, (rows, cols)))
X2.todense()
np.vstack([rows, cols])
indptr = np.r_[np.searchsorted(rows, np.unique(rows)), len(rows)]
indptr
X3 = sparse.csr_matrix((vals, cols, indptr))
X3
print(X3)
X3.todense()
X4 = X2.tocsr()
X4
print(X4)
X5 = X2.tocsc()
X5
print(X5)
rows = np.repeat([0, 1], 4)
cols = np.repeat([0, 1], 4)
vals = np.arange(8)
rows, cols, vals
X6 = sparse.coo_matrix((vals, (rows, cols)))
X6.todense()
y_true = np.random.randint(0, 2, 100)
y_pred = np.random.randint(0, 2, 100)
vals = np.ones(100).astype("int")
y_true, y_pred
vals.shape, y_true.shape, y_pred.shape
X7 = sparse.coo_matrix((vals, (y_true, y_pred)))
X7.todense()
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
y_true = ["cat", "ant", "cat", "cat", "ant", "bird"]
y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"]
confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"])
Pandas
Series 与 Dataframe
- Series:键值对形成的二序序列,有标签的numpy一维数组
- Dataframe:行列值三元序列(类似excel表),有标签的numpy二维数组
- Input/output
- General functions
- Pandas arrays
- Index objects
- Date offsets
- Window
- GroupBy
- Resampling
- Style
- Plotting
- General utility functions
- Extensions

向量化字符串操作
Pandas提供了一系列向量化字符串操作(vectorized string operation),极大地提高了字符串清洗效率。Pandas为包含字符串的Series和Index对象提供了str属性,既可以处理字符串,又可以处理缺失值。
字符串方法
所有Python内置的字符串方法都被复制到Pandas的向量化字符串方法中:
len() | lower() | translate() | islower()
ljust() | upper() | startswith() | isupper()
rjust() | find() | endswith() | isnumeric()
center() | rfind() | isalnum() | isdecimal()
zfill() | index() | isalpha() | split()
strip() | rindex() | isdigit() | rsplit()
rstrip() | capitalize() | isspace() | partition()
lstrip() | swapcase() | istitle() | rpartition()
这些方法的返回值并不完全相同,例如
lower()方法返回字符串,len()方法返回数值,startswith('T')返回布尔值,split()方法返回列表
monte = pd.Series(
(
"Gerald R. Ford",
"James Carter",
"Ronald Reagan",
"George H. W. Bush",
"William J. Clinton",
"George W. Bush",
"Barack Obama",
"Donald J. Trump",
)
)
monte.str.len()
正则表达式
有一些方法支持正则表达式处理字符串。下面是Pandas根据Python标准库的re模块函数实现的API:
| 方法 | 描述 |
|---|---|
match() |
对每个元素调用re.match(),返回布尔类型值 |
extract() |
对每个元素调用re.match(),返回匹配的字符串组(groups) |
findall() |
对每个元素调用re.findall()
|
replace() |
用正则模式替换字符串 |
contains() |
对每个元素调用re.search(),返回布尔类型值 |
count() |
计算符合正则模式的字符串的数量 |
split() |
等价于str.split(),支持正则表达式 |
rsplit() |
等价于str.rsplit(),支持正则表达式 |
monte.str.extract('([A-Za-z]+)')
找出所有开头和结尾都是辅音字母的名字——这可以用正则表达式中的开始符号(^)与结尾符号($)来实现:
monte.str.findall(r'^[^AEIOU].*[^aeiou]$')
其他字符串方法
还有其他一些方法可以实现更方便的操作
| 方法 | 描述 |
|---|---|
get() |
获取元素索引位置上的值,索引从0开始 |
slice() |
对元素进行切片取值 |
slice_replace() |
对元素进行切片替换 |
cat() |
连接字符串(此功能比较复杂,建议阅读文档) |
repeat() |
重复元素 |
normalize() |
将字符串转换为Unicode规范形式 |
pad() |
在字符串的左边、右边或两边增加空格 |
wrap() |
将字符串按照指定的宽度换行 |
join() |
用分隔符连接Series的每个元素 |
get_dummies() |
按照分隔符提取每个元素的dummy变量,转换为独热(one-hot)编码的DataFrame
|
monte.str[0:3]
get()与slice()操作还可以在split()操作之后使用。例如,要获取每个姓名的姓(last name),可以结合使用split()与get():
monte.str.split().str.get(-1)
full_monte = pd.DataFrame(
{
"name": monte,
"info": ["B|C|D", "B|D", "A|C", "B|D", "B|C", "A|C", "B|D", "B|C|D"],
}
)
full_monte
full_monte['info'].str.get_dummies('|')
date = pd.to_datetime("4th of May, 2020")
date
date.strftime('%A')
可以直接进行NumPy类型的向量化运算:
date + pd.to_timedelta(np.arange(12), 'D')
index = pd.DatetimeIndex(["2019-01-04", "2019-02-04", "2020-03-04", "2020-04-04"])
data = pd.Series([0, 1, 2, 3], index=index)
data
直接用日期进行切片取值:
data['2020-02-04':'2020-04-04']
直接通过年份切片获取该年的数据:
data['2020']
Pandas时间序列数据结构
本节将介绍Pandas用来处理时间序列的基础数据类型。
-
时间戳,Pandas提供了
Timestamp类型。本质上是Python的原生datetime类型的替代品,但是在性能更好的numpy.datetime64类型的基础上创建。对应的索引数据结构是DatetimeIndex。 -
时间周期,Pandas提供了
Period类型。这是利用numpy.datetime64类型将固定频率的时间间隔进行编码。对应的索引数据结构是PeriodIndex。 -
时间增量或持续时间,Pandas提供了
Timedelta类型。Timedelta是一种代替Python原生datetime.timedelta类型的高性能数据结构,同样是基于numpy.timedelta64类型。对应的索引数据结构是TimedeltaIndex。
最基础的日期/时间对象是Timestamp和DatetimeIndex,对pd.to_datetime()传递一个日期会返回一个Timestamp类型,传递一个时间序列会返回一个DatetimeIndex类型:
from datetime import datetime
dates = pd.to_datetime(
[datetime(2020, 7, 3), "4th of July, 2020", "2020-Jul-6", "07-07-2020", "20200708"]
)
dates
任何DatetimeIndex类型都可以通过to_period()方法和一个频率代码转换成PeriodIndex类型。
用'D'将数据转换成单日的时间序列:
dates.to_period('D')
当用一个日期减去另一个日期时,返回的结果是TimedeltaIndex类型:
dates - dates[0]
pd.date_range('2020-07-03', '2020-07-10')
日期范围不一定非是开始时间与结束时间,也可以是开始时间与周期数periods:
pd.date_range('2020-07-03', periods=8)
通过freq参数改变时间间隔,默认值是D。例如,可以创建一个按小时变化的时间戳:
pd.date_range('2020-07-03', periods=8, freq='H')
如果要创建一个有规律的周期或时间间隔序列,有类似的函数pd.period_range()和pd.timedelta_range()。下面是一个以月为周期的示例:
pd.period_range('2020-07', periods=8, freq='M')
以小时递增:
pd.timedelta_range(0, periods=10, freq='H')
时间频率与偏移量
Pandas时间序列工具的基础是时间频率或偏移量(offset)代码。就像之前见过的D(day)和H(hour)代码,可以设置任意需要的时间间隔
| 代码 | 描述 | 代码 | 描述 |
|---|---|---|---|
D |
天(calendar day,按日历算,含双休日) | B |
天(business day,仅含工作日) |
W |
周(weekly) | ||
M |
月末(month end) | BM |
月末(business month end,仅含工作日) |
Q |
季节末(quarter end) | BQ |
季节末(business quarter end,仅含工作日) |
A |
年末(year end) | BA |
年末(business year end,仅含工作日) |
H |
小时(hours) | BH |
小时(business hours,工作时间) |
T |
分钟(minutes) | ||
S |
秒(seconds) | ||
L |
毫秒(milliseonds) | ||
U |
微秒(microseconds) | ||
N |
纳秒(nanoseconds) |
月、季、年频率都是具体周期的结束时间(月末、季末、年末),而有一些以S(start,开始) 为后缀的代码表示日期开始。
| 代码 | 频率 |
|---|---|
MS |
月初(month start) |
BMS |
月初(business month start,仅含工作日) |
QS |
季初(quarter start) |
BQS |
季初(business quarter start,仅含工作日) |
AS |
年初(year start) |
BAS |
年初(business year start,仅含工作日) |
另外,可以在频率代码后面加三位月份缩写字母来改变季、年频率的开始时间:
-
Q-JAN、BQ-FEB、QS-MAR、BQS-APR等 -
A-JAN、BA-FEB、AS-MAR、BAS-APR等
也可以在后面加三位星期缩写字母来改变一周的开始时间:
-
W-SUN、W-MON、W-TUE、W-WED等
还可以将频率组合起来创建的新的周期。例如,可以用小时(H)和分钟(T)的组合来实现2小时30分钟:
pd.timedelta_range(0, periods=9, freq="2H30T")
所有这些频率代码都对应Pandas时间序列的偏移量,具体内容可以在pd.tseries.offsets模块中找到。例如,可以用下面的方法直接创建一个工作日偏移序列:
from pandas.tseries.offsets import BDay
pd.date_range('2020-07-01', periods=5, freq=BDay())
%%file snowball.py
from datetime import datetime
import requests
import pandas as pd
def get_stock(code):
response = requests.get(
"https://stock.xueqiu.com/v5/stock/chart/kline.json",
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
},
params=(
("symbol", code),
("begin", int(datetime.now().timestamp() * 1000)),
("period", "day"),
("type", "before"),
("count", "-5000"),
("indicator", "kline"),
),
cookies={"xq_a_token": "328f8bbf7903261db206d83de7b85c58e4486dda",},
)
if response.ok:
d = response.json()["data"]
data = pd.DataFrame(data=d["item"], columns=d["column"])
data.index = data.timestamp.apply(
lambda _: pd.Timestamp(_, unit="ms", tz="Asia/Shanghai")
)
return data
else:
print("stock error")
from snowball import get_stock
data = get_stock("SH600519") # 贵州茅台
data.tail()
gzmt = data['close']
gzmt.plot(figsize=(15,8));
plt.title('贵州茅台历史收盘价');

plt.figure(figsize=(15, 8))
gzmt.plot(alpha=0.5, style="-")
gzmt.resample("BA").mean().plot(style=":")
gzmt.asfreq("BA").plot(style="--")
plt.title('贵州茅台历史收盘价年末采样');
plt.legend(["input", "resample", "asfreq"], loc="upper left");

在每个数据点上,
resample反映的是上一年的均值,而asfreq反映的是上一年最后一个工作日的收盘价。在进行上采样(up-sampling,增加采样频率,从月到日)时,
resample()与asfreq()的用法大体相同,
两种方法都默认将采样作为缺失值NaN,与pd.fillna()函数类似,asfreq()有一个method参数可以设置填充缺失值的方式。对数据按天进行重采样(包含周末),asfreq()向前填充与向后填充缺失值的结果对比:
fig, ax = plt.subplots(2, sharex=True, figsize=(15, 8))
data = gzmt.iloc[-14:]
ax[0].set_title("贵州茅台近两周收盘价")
data.asfreq("D").plot(ax=ax[0], marker="o")
ax[1].set_title("采样缺失值填充方法对比")
data.asfreq("D", method="bfill").plot(ax=ax[1], style="-o")
data.asfreq("D", method="ffill").plot(ax=ax[1], style="--o")
ax[1].legend(["back-fill", "forward-fill"]);

fig, ax = plt.subplots(3, sharey=True, figsize=(15, 8))
# 对数据应用时间频率,用向后填充解决缺失值
gzmt = gzmt.asfreq("D", method="pad")
gzmt.plot(ax=ax[0])
gzmt.shift(900).plot(ax=ax[1])
gzmt.tshift(900).plot(ax=ax[2])
# 设置图例与标签
local_max = pd.to_datetime("2010-01-01")
offset = pd.Timedelta(900, "D")
ax[0].legend(["input"], loc=2)
ax[0].get_xticklabels()[5].set(weight="heavy", color="red")
ax[0].axvline(local_max, alpha=0.3, color="red")
ax[1].legend(["shift(900)"], loc=2)
ax[1].get_xticklabels()[5].set(weight="heavy", color="red")
ax[1].axvline(local_max + offset, alpha=0.3, color="red")
ax[2].legend(["tshift(900)"], loc=2)
ax[2].get_xticklabels()[1].set(weight="heavy", color="red")
ax[2].axvline(local_max + offset, alpha=0.3, color="red");

shift(900)将数据向前推进了900天,这样图形中的一段就消失了(最左侧就变成了缺失值),而tshift(900)方法是将时间索引值向前推进了900天。
可以用迁移后的值来计算gzmtle股票一年期的投资回报率:
ROI = (gzmt.tshift(-365) / gzmt - 1) * 100
ROI.plot(figsize=(15, 8))
plt.title("贵州茅台年度ROI");

rolling = gzmt.rolling(365, center=True)
data = pd.DataFrame(
{
"input": gzmt,
"one-year rolling_mean": rolling.mean(),
"one-year rolling_std": rolling.std(),
}
)
ax = data.plot(style=["-", "--", ":"], figsize=(15, 8))
ax.lines[0].set_alpha(0.8)
plt.title("贵州茅台一年期移动平均值和标准差");

nrows, ncols = 100000, 100
rng = np.random.RandomState(42)
df1, df2, df3, df4 = (pd.DataFrame(rng.rand(nrows, ncols)) for i in range(4))
%timeit df1 + df2 + df3 + df4
%timeit pd.eval('df1 + df2 + df3 + df4')
result1 = -df1 * df2 / (df3 + df4)
result2 = pd.eval('-df1 * df2 / (df3 + df4)')
np.allclose(result1, result2)
result1 = (df1 < df2) & (df2 <= df3) & (df3 != df4)
result2 = pd.eval('df1 < df2 <= df3 != df4')
np.allclose(result1, result2)
result1 = (df1 < 0.5) & (df2 < 0.5) | (df3 < df4)
result2 = pd.eval('(df1 < 0.5) & (df2 < 0.5) | (df3 < df4)')
np.allclose(result1, result2)
还可以在布尔类型的代数式中使用and和or:
result3 = pd.eval('(df1 < 0.5) and (df2 < 0.5) or (df3 < df4)')
np.allclose(result1, result3)
result1 = df2.T[0] + df3.iloc[1]
result2 = pd.eval('df2.T[0] + df3.iloc[1]')
np.allclose(result1, result2)
df = pd.DataFrame(rng.rand(1000, 3), columns=["A", "B", "C"])
df.head()
result1 = (df['A'] + df['B']) / (df['C'] - 1)
result2 = pd.eval("(df.A + df.B) / (df.C - 1)")
np.allclose(result1, result2)
result3 = df.eval('(A + B) / (C - 1)')
np.allclose(result1, result3)
df.eval('D = (A + B) / C', inplace=True)
df.head()
还可以修改已有的列:
df.eval('D = (A - B) / C', inplace=True)
df.head()
column_mean = df.mean(1)
result1 = df['A'] + column_mean
result2 = df.eval('A + @column_mean')
np.allclose(result1, result2)
@符号表示变量名称(Python对象的命名空间)而非列名称(DataFrame列名称的命名空间)。需要注意的是,@符号只能在DataFrame.eval()方法中使用,而不能在pandas.eval()函数中使用,因为pandas.eval()函数只能获取一个(Python)命名空间的内容。
result1 = df[(df.A < 0.5) & (df.B < 0.5)]
result2 = pd.eval('df[(df.A < 0.5) & (df.B < 0.5)]')
np.allclose(result1, result2)
result3 = df.query('A < 0.5 and B < 0.5')
np.allclose(result1, result3)
Cython与Numba
Cython
直接将Python代码编译成C/C++,然后编译成Python模块:
- 用Python代码调用原生C/C++
- 用静态类型声明让Python代码达到C语言的性能
- 代码变得更啰嗦,会破坏可维护性和可读性

%load_ext Cython
# %reload_ext Cython
%%cython
cdef int a = 0
for i in range(10):
a += i
print(a)
- 用Cython把
.pyx文件编译(翻译)成.c文件。这些文件里的源代码,基本都是纯Python代码加上一些Cython代码 -
.c文件被C语言编译器编译成.so库,这个库之后可以导入Python - 编译代码有3种方法:
- 创建一个
distutils模块配置文件,生成自定义的C语言编译文件。 - 运行
cython命令将.pyx文件编译成.c文件,然后用C语言编译器(gcc)把C代码手动编译成库文件。 - 用
pyximport,像导入.py文件一样导入.pyx直接使用。
- 创建一个
%%bash
pwd
rm -rf test_cython
mkdir test_cython
ls
cd test_cython
pwd
%%file test.pyx
def join_n_print(parts):
"""merge string list with space"""
print(' '.join(parts))
ls
%%cython
import pyximport; pyximport.install()
from test_cython.test import join_n_print
join_n_print(["This", "is", "a", "test"])
%%file setup.py
from distutils.core import setup
from Cython.Build import cythonize
setup(
name="Test app", ext_modules=cythonize("test.pyx"),
)
!python setup.py build_ext --inplace
ls
!tree build/
Cython通常都需要导入两类文件:
- 定义文件:文件扩展名.pxd,是Cython文件要使用的变量、类型、函数名称的C语言声明。
-
实现文件:文件扩展名.pyx,包括在
.pxd文件中已经定义好的函数实现。
%%file dishes.pxd
cdef enum otherstuff:
sausage, eggs, lettuce
cdef struct spamdish:
int oz_of_spam
otherstuff filler
%%file restaurant.pyx
cimport dishes
from dishes cimport spamdish
cdef void prepare(spamdish * d):
d.oz_of_spam = 42
d.filler = dishes.sausage
def serve():
cdef spamdish d
prepare( & d)
print(f"{d.oz_of_spam} oz spam, filler no. {d.filler}")
ls
from test_cython.test import join_n_print
join_n_print(["a", "b", "c"])
定义函数类型
Cython除了可以调用标准C语言函数,还可以定义两种函数:
-
标准Python函数:与纯Python代码中声明的函数完全一样,用
cdef关键字定义。接受Python对象作为参数,也返回Python对象 -
C函数:是标准函数的优化版,用Python对象或C语言类型作为参数,返回值也可以是两种类型。要定义这种函数,用
cpdef关键字定义
虽然这两种函数都可以通过Cython模块调用。但是从Python代码(.py)中调用函数,必须是标准Python函数,或者
cpdef关键字定义函数。这个关键字会创建一个函数的封装对象。当用Cython调用函数时,它用C语言对象;当从Python代码中调用函数时,它用纯Python函数。
下面是一个纯Python函数,因此Cython会让这个函数返回并接收一个Python对象,而不是C语言原生类型。
%%cython
cdef full_python_function (x):
return x**2
这个函数使用了cpdef关键字,所以它既是一个标准函数,也是一个优化过的C语言函数。
%%cython
cpdef int c_function(int x):
return x**2
lon1, lat1, lon2, lat2 = 110.0123, 23.32435, 129.1344, 25.5465
num = 5000000
%%file great_circle_py.py
from math import pi, acos, cos, sin
def great_circle(lon1, lat1, lon2, lat2):
radius = 6371 # 公里
x = pi / 180
a = (90 - lat1) * (x)
b = (90 - lat2) * (x)
theta = (lon2 - lon1) * (x)
c = acos((cos(a) * cos(b)) + (sin(a) * sin(b) * cos(theta)))
return radius * c
from great_circle_py import great_circle
for i in range(num):
great_circle(lon1, lat1, lon2, lat2)
%%cython -a
from math import pi, acos, cos, sin
def great_circle(lon1, lat1, lon2, lat2):
radius = 6371 # 公里
x = pi / 180
a = (90 - lat1) * (x)
b = (90 - lat2) * (x)
theta = (lon2 - lon1) * (x)
c = acos((cos(a) * cos(b)) + (sin(a) * sin(b) * cos(theta)))
return radius * c
%%file great_circle_cy_v1.pyx
from math import pi, acos, cos, sin
def great_circle(double lon1, double lat1, double lon2, double lat2):
cdef double a, b, theta, c, x, radius
radius = 6371 # 公里
x = pi/180
a = (90-lat1)*(x)
b = (90-lat2)*(x)
theta = (lon2-lon1)*(x)
c = acos((cos(a)*cos(b)) + (sin(a)*sin(b)*cos(theta)))
return radius*c
%%file great_circle_setup_v1.py
from distutils.core import setup
from Cython.Build import cythonize
setup(
name='Great Circle module v1',
ext_modules=cythonize("great_circle_cy_v1.pyx"),
)
!python great_circle_setup_v1.py build_ext --inplace
ls
from great_circle_cy_v1 import great_circle
for i in range(num):
great_circle(lon1, lat1, lon2, lat2)
%%cython -a
from math import pi, acos, cos, sin
def great_circle(double lon1, double lat1, double lon2, double lat2):
cdef double a, b, theta, c, x, radius
radius = 6371 # 公里
x = pi/180
a = (90-lat1)*(x)
b = (90-lat2)*(x)
theta = (lon2-lon1)*(x)
c = acos((cos(a)*cos(b)) + (sin(a)*sin(b)*cos(theta)))
return radius*c
%%file great_circle_cy_v2.pyx
cdef extern from "math.h":
float cosf(float theta)
float sinf(float theta)
float acosf(float theta)
cpdef double great_circle(double lon1, double lat1, double lon2, double lat2):
cdef double a, b, theta, c, x, radius
cdef double pi = 3.141592653589793
radius = 6371 # 公里
x = pi/180
a = (90-lat1)*(x)
b = (90-lat2)*(x)
theta = (lon2-lon1)*(x)
c = acosf((cosf(a)*cosf(b)) + (sinf(a)*sinf(b)*cosf(theta)))
return radius*c
%%file great_circle_setup_v2.py
from distutils.core import setup
from Cython.Build import cythonize
setup(
name="Great Circle module v2", ext_modules=cythonize("great_circle_cy_v2.pyx"),
)
!python great_circle_setup_v2.py build_ext --inplace
from great_circle_cy_v2 import great_circle
for i in range(num):
great_circle(lon1, lat1, lon2, lat2)
%%cython -a
cdef extern from "math.h":
float cosf(float theta)
float sinf(float theta)
float acosf(float theta)
cpdef double great_circle(double lon1, double lat1, double lon2, double lat2):
cdef double a, b, theta, c, x, radius
cdef double pi = 3.141592653589793
radius = 6371 # 公里
x = pi/180
a = (90-lat1)*(x)
b = (90-lat2)*(x)
theta = (lon2-lon1)*(x)
c = acosf((cosf(a)*cosf(b)) + (sinf(a)*sinf(b)*cosf(theta)))
return radius*c
Numba
通过装饰器控制Python解释器把函数转变成机器码,实现了与C和Cython同样的性能,但是不需要用新的解释器或者写C代码。可以按需生成优化(JIT)的机器码,甚至可以编译成CPU或GPU可执行代码。
- JIT即时代码生成(On-the-fly code generation)
- CPU和GPU原生代码生成
- 与Numpy相关包交互
a = np.random.rand(1000, 1000)
def sum2d(arr):
M, N = arr.shape
result = 0
for i in range(M):
for j in range(N):
result += arr[i, j]
return result
%timeit -r3 -n10 sum2d(a)
from numba import jit
# jit装饰器告诉Numba编译函数,当函数被调用时,Numba再引入参数类型
@jit
def sum2d(arr):
M, N = arr.shape
result = 0
for i in range(M):
for j in range(N):
result += arr[i, j]
return result
%timeit sum2d(a)
from numba import jit, float64
@jit(float64(float64[:, :]))
def sum2d(arr):
M, N = arr.shape
result = 0
for i in range(M):
for j in range(N):
result += arr[i, j]
return result
%timeit sum2d(a)
@jit配置函数签名的常用类型如下。
-
void:函数返回值类型,表示不返回任何结果。 -
intp和uintp:指针大小的整数,分别表示签名和无签名类型。 -
intc和uintc:相当于C语言的整型和无符号整型。 -
int8、int16、int32和int64:固定宽度整型(无符号整型前面加u,比如uint8)。 -
float32和float64:单精度和双精度浮点数类型。 -
complex64和complex128:单精度和双精度复数类型。 - 数组可以用任何带索引的数值类型表示,比如
float32[:]就是一维浮点数数组类型,int32[:,:]就是二维整型数组。
编译选项
- 非GIL模式:把
nogil=True属性传到装饰器,就可以不受GIL的限制,多线程系统的常见问题(一致性、数据同步、竞态条件等)就可以解决。 -
无Python模式:可以通过
nopython参数设置Numba的编译模式:-
object模式:默认模式,产生的代码可以处理所有Python对象,并用C API完成Python对象上的操作; -
nopython模式:可以不调用C API而生成更高效的代码,不过只有一部分函数和方法可以使用:- 函数中表示数值的所有原生类型都可以被引用
- 函数中不可以分配新内存
-
- 缓存模式:避免重复调用,通过
cache=True将结果保证在缓存文件中 -
并行模式:通过
parallel=True并行计算,必须配合nopython=True使用
@jit(nopython=True)
def sum2d(arr):
M, N = arr.shape
result = 0
for i in range(M):
for j in range(N):
result += arr[i, j]
return result
%timeit sum2d(a)
from numba import prange
@jit(parallel=True, nopython=True)
def sum2d(arr):
M, N = arr.shape
result = 0
for i in prange(M):
for j in range(N):
result += arr[i, j]
return result
%timeit sum2d(a)
- @njit:@jit(nopython=True)的
- @vectorize与@guvectorize:支持NumPy的通用函数(ufunc)
- @stencil:定义一个核函数实现stencil(模版)类操作
- @jitclass:jit编译python类
- @cfunc:定义可以被C/C++直接调用的函数
- @overload:注册一个在nopython模式使用自定义函数
pyspark
import findspark
findspark.init(spark_home="/home/junjiet/conda/lib/python3.7/site-packages/pyspark")
from pyspark.sql import SparkSession, dataframe
from pyspark import SparkConf, SparkContext
from pyspark.sql.types import *
from pyspark.sql import functions as F
sparkConf = SparkConf().set("spark.sql.execution.arrow.enabled", "false")
spark = SparkSession.builder.config(conf=sparkConf).enableHiveSupport().getOrCreate()
sc = SparkContext.getOrCreate()
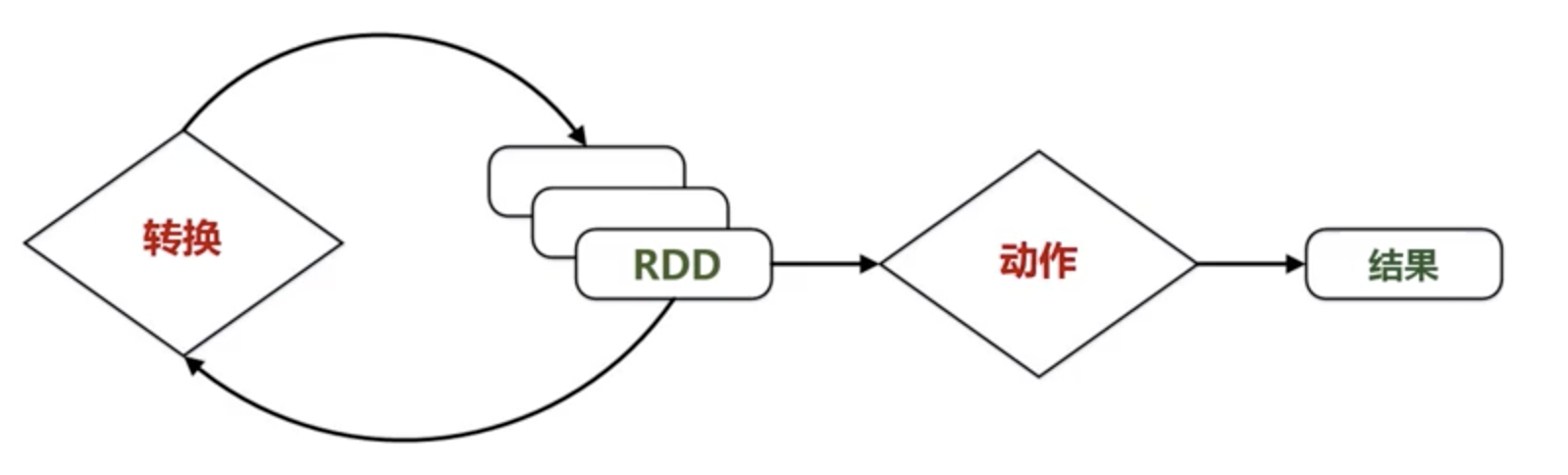
rdd = sc.parallelize([1, 2, 2, 3, 3, 4, 5])
rdd.filter(lambda x: x % 2 == 0).collect()

rdd.count()
rdd.distinct().collect()


schema = (
StructType()
.add("user_id", "string")
.add("country", "string")
.add("browser", "string")
.add("OS", "string")
.add("age", "integer")
.add("salary", "double")
)
df = spark.createDataFrame(
[
("A203", "India", "Chrome", "WIN", 33, 12.34),
("A201", "China", "Safari", "MacOS", 45, 14.56),
("A205", "UK", "Mozilla", "Linux", 25, 16.78),
("A206", "China", "Chrome", "MacOS", 68, 23.45),
],
schema=schema,
)
df.printSchema()
df.show()
df.filter(df["age"] > 30)
df.filter(df["age"] > 30).count()
df.where((df["age"] > 30) & (df["country"] == "China")).show()
df.toPandas()
from pyspark.sql import dataframe
def spark_shape(self):
return (self.count(), len(self.columns))
dataframe.DataFrame.shape = spark_shape
df.shape()
from pyspark.sql.functions import udf
def age_category(age):
if 18 <= age < 30:
return "A"
elif age < 60:
return "B"
else:
return "C"
age_udf = udf(age_category, StringType())
df.withColumn("age_category", age_udf(df["age"])).show()
min_sal, max_sal = df.agg(F.min("salary"), F.max("salary")).collect()[0]
min_sal, max_sal
from pyspark.sql.functions import pandas_udf
def scaled_salary(salary):
scaled_sal = (salary - min_sal) / (max_sal - min_sal)
return scaled_sal
scaling_udf = pandas_udf(scaled_salary, DoubleType())
df.select(df["salary"], scaling_udf(df["salary"])).show()

- 捕蛇者说 中文python播客,有趣有料
- pandas_profiling EDA可视化报表,支持导出html格式
- pandarallel CPU并行加速,apply、map、groupby与rolling等应用场景
- jax NumPy的GPU加速——谷歌开源,jakavdp参与开发
- cudf Datafame的GPU加速
- koalas Databricks按照pandas实现的pyspark接口